
Integrative Privacy

Jake Ottenwaelder and Thenushaa Kandiah discuss technical designations and how these definitions translate across regulatory frameworks.
The world of data privacy is changing faster than ever. As legislative frameworks evolve to meet growing technical innovations, the precision and specificity of our privacy vocabulary must adapt to these changes in real time.
A popularly cited article states that 87% of the U.S. population is identifiable through three publicly available data points: name, date of birth, and zip code. Since its publication in 2000, we’ve seen new regulations, exponential growth in consumer data collection, and maturing machine learning tools – all of which complicate and intensify data privacy risks.
This article illustrates the differences between the three important terms in major data privacy laws and legislation – de-identification, anonymization, and pseudonymization – from a risk-based perspective; analyzes their place within the General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), and Health Insurance Portability and Accountability Act (HIPAA); and delve into their implications for modern identifiability risks.
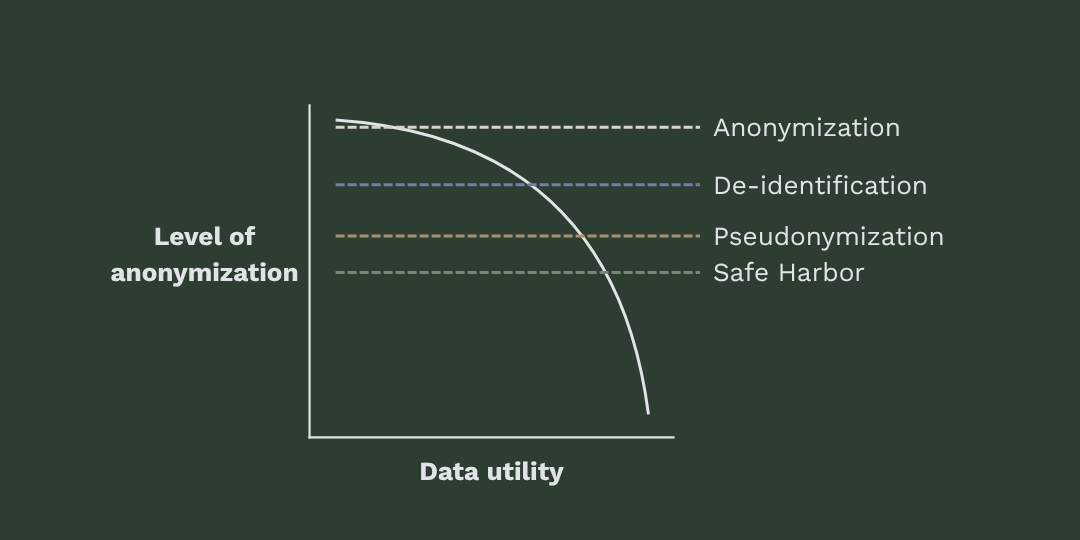
Across global regulatory landscapes, the terms de-identification, anonymization, and pseudonymization define the legal boundaries of data utility and privacy. While many of us may use these terms interchangeably in casual discourse, they carry distinct legal meanings with varying obligations under different laws.
Recital 26 of the GDPR classifies anonymized data as, “information which does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable.”
Pseudonymized data is “personal data [that] can no longer be attributed to a specific data subject without the use of additional information[…]” as stated in Art. 4(5) of the GDPR.
De-identified data is data that “cannot reasonably identify, relate to, describe, be capable of being associated with, or be linked, directly or indirectly, to a particular consumer,” according to Cal. Civ. Code § 1798.140(o)(2).
According to 45 CFR § 164.514(a)-(c) of HIPAA, de-identified protected health information (PHI), “does not identify an individual with respect to which there is no reasonable basis to believe that the information can be used to identify an individual.” HIPAA offers two formal pathways for de-identifying PHI:
Among these designations, the key distinguishing factors are the perspective, permanence, and re-identification risk.
Privacy professionals leverage a variety of technical methods to achieve each standard. We’ll start in reverse order from least to greatest level of anonymization, using a hypothetical patient medical record as an example.
Jane Doe lives in a rural region of California, and she has ALS.
Safe Harbor requires the removal of 18 direct identifiers to achieve de-identification. This framework uses suppression, or the explicit removal of these direct identifiers.
Of note, Safe Harbor does not account for indirect identifiers, which can be used in combination with other identifiers to re-identify an individual. Therefore, the remaining ethnicity and diagnostic code – which is the international classification for Jane’s condition – retain re-identification risk.
Pseudonymization replaces identifiers in the field value with pseudonyms. This can be achieved through hashing or encryptions. In this case, the patient’s name, email, and medical record number (MRN) have been hashed and replaced, leaving the remaining fields intact.
Despite pseudonymization, re-identification risks remain. Available datasets pulled alongside this record could re-identify the patient. It is also possible to reverse-engineer pseudonymized data by mapping hashed pseudonyms back to the original values.
De-identification is achieved by masking identifiers and generalizing the data to reduce re-identification risk. Masking obscures the data values (ex. “Jane Doe” changed to “nil”), while generalization hides identifiers in broader data categories (ex. Date of birth to birth month and year).
De-identified data can still be mapped between tables using internal identifiers. Most often, though, it cannot be reversed or mapped to original data.
Anonymization requires a range of technical capabilities, including:
These changes are irreversible, so the data cannot be mapped back to individuals and re-identification risk is significantly reduced. We’ve applied some of these techniques to Jane’s record:
More advanced level techniques like noise addition fall into the differential privacy techniques that go beyond standard de-identification. However, users can still be re-identified after some of these techniques have been applied.
We operate under a few basic assumptions:
They are all wrong. Here’s what can happen if a bad actor gets a hold of your dataset.
Linkage attacks occur when indirect personal identifiers can be linked across tables to gain more information about the data subject and potentially re-identify them. In Jane’s case, her medical record could be linked to public voter registration lists based on her rural zip code or date of birth.
Background attacks refer to when publicly available data, or background knowledge, is applied to a dataset to determine specific characteristics or to re-identify an individual. For example, if Jane participated in the ALS Ice Bucket Challenge and disclosed her condition in a Facebook post, a bad actor could use this public information to match the medical record to her identity.
Inferential attacks involve using statistical methods to calculate the distribution of data and find any outliers in the dataset. By monitoring the dataset over time, bad actors can identify new individuals added to the dataset by deciphering the impact of new information on the statistical distribution of the dataset. If Jane’s record were added to a new dataset, a bad actor could re-identify her by analyzing how the addition altered statistical characteristics.
Singling out can take on two forms: unique record identification and outlier exploitation. With unique record identification, bad actors can single out identifying records that are so statistically unique within the dataset that they can only belong to one individual, even without the use of external data. Outlier exploitation involves targeting records with extreme or unusual values that make them highly distinguishable from the rest of the dataset. Because Jane has a rare medical condition and lives in a rural zip code, she could be singled out as a unique record or outlier.
As machine learning proliferates, the risk of these attacks grows even more likely.
Safe Harbor is the easiest to implement because HIPAA offers a “rulebook” of identifiers to remove, and no large technical processes are required to suppress these identifiers in a dataset. Data utility can be maintained based on indirect or aggregated identifiers, but linkability risk remains.
Pseudonymization is broadly implemented with relative ease for non-production environments or internal use. Linkability risk remains since hash or modified pseudonyms can be linked back to original identifiers. The key trade-off is that pseudonymized data retains a higher level of data utility, which holds benefits for business or research purposes.
.png)
De-identification falls into the middle range of anonymization level and data utility. It offers lower implementation costs, and it’s easy to scale through simple algorithms performed locally on datasets. De-identified data has lower linkability risks and lower data utility compared to pseudonymized data.
Anonymization is the most conservative, risk-averse technical approach, with the highest level of anonymization and the lowest level of data utility. Implementation costs are high, and anonymized datasets must be maintained as data changes over time. Planning is key for anonymized data. Before moving forward with anonymization, it must be decided where data utility is needed and what metrics an organization requires.
However, “anonymized data” is more of a theoretical concept rather than a tangible standard. There is no level of anonymization where there is a true zero risk for re-identification. A truly anonymous dataset is an empty one. While true anonymization is theoretically possible, it is not practically possible for most organizations while maintaining a level of data utility.
Under HIPAA, expert determination can verify that the “risk is very small” that data alone or in combination with “reasonably available information” can identify a data subject. Safe Harbor-compliant datasets do not meet the legal requirements for GDPR, since it does not account for indirect identifiers or interaction-level data.
Similarly to Safe Harbor datasets, pseudonymized data does not meet the legal requirements for GDPR. Because the re-identification risk and level of anonymization is high, pseudonymized data must be treated and managed as personal data under the GDPR.
Under CCPA, de-identified data must not “reasonably be used” to infer or link to an individual, and a business can use “technical safeguards” and “business processes” to prevent re-identification and prohibit business from attempting to re-identify. While de-identified data is compliant under CCPA, it still does not meet the legal requirements set by the GDPR.
Under GDPR, anonymized data must “not relate” to a natural personal, and the data subject is “no longer identifiable” after the data has been rendered anonymous. Anonymized data is no longer considered personal information, so it can be freely used for internal business purposes under GDPR.
Based on the earlier discussions, we discussed three main differences when choosing which technique or standard you want to align your dataset with.
This article was originally published in collaboration with the California Lawyer's Association Privacy Law Section as a companion article to the webinar of the same name hosted on March 26, 2026.
The full webinar is available via InReach.
.png)
July 2, 2026

May 14, 2026
© Integrative Privacy 2026